

It is now 2020. The EU Commission has introduced new legislation aimed at improving the traceability and safe management of medical devices. This will take legal force within the coming months, so the clock is ticking. Issuing agencies are ensuring that they have viable solutions for the new identifiers introduced by the regulations. National bodies are getting ready to support and audit the sale of medical devices in accordance with the changing standards. And manufacturers of medical devices are working hard to understand the implications of the regulations to their business, obtain the necessary company identifiers from the issuing agencies, and to understand how to correctly construct, apply and record their family of device identifiers in order to comply with the legislation.
A Call to Action
In January 2019 an ad hoc subgroup of the GS1 Barcodes and Identification Technical Group (BCID TG), comprised of Sprague Ackley, Terry Burton, Jackson He, Ph.D., Clive Hohberger, PhD., Steven Keddie and George Wright IV, was approached to develop an application-specific variant of the GS1 Global Model Number that would be compliant with EU regulatory requirements for a new unique device identifier known as the “Basic UDI-DI” for use in regulated healthcare applications.
As part of the process of being designated as an authorized Issuing Agency for medical device identifiers under the European Union Medical Device Regulation (MDR) and In-Vitro Diagnostic Regulation (IVDR), GS1 had a four month timeline during which to publish a critical update to the GS1 General Specifications, namely, to define restrictions compatible with healthcare sector requirements for the existing GS1 Global Model Number identifier that would apply when the identifier was used for EU-regulated medical devices.
The Basic UDI-DI is described by the EU MDR as “the main key for records in the UDI database and is referenced in relevant certificates and EU declarations of conformity.” It is printed as human readable text to be manually key-entered. As with other critical identification keys, the Basic UDI-DI identifier must have inherent data format security to protect against erroneous data entry. This protection is therefore included within the definition of the identifier itself by means of a checksum. The onus of defining an appropriate checksum algorithm is placed on the issuing agency.
The generic GS1 Global Model Number is defined in the GS1 General Specifications as a data element that consists of up to 30 characters, each of which is a member of “GS1 Application Identifier encodable character set 82”. This character set defines the permissible values for use when encoding GS1 element strings using GS1 Application Identifiers and is itself a subset of the printable characters from the ubiquitous ISO/IEC 646 (“ASCII”) character set.

The generic GS1 Global Model Number does not include any inherent data protection so it must be augmented with some form of check character validation if it is to be used as a Basic UDI-DI. Additionally, it is necessary to restrict the message to 25 characters to meet the definition of a Basic UDI-DI.
| The GS1 Global Model Number is the GS1 identification key used to identify a product model or product family based on attributes common to the model or family as defined by industry or regulation. The GS1 Global Model Number enables users to uniquely identify the product model through the entire life cycle of the product: Design → Production → Procurement → Use → Maintenance → Disposal. Critically, the GS1 Global Model Number is not a replacement for the GS1 Global Trade Item Number (GTIN); nor is the GTIN a replacement for the GS1 Global Model Number. Moreover, when the GS1 Global Model Number identification key is used to represent the EU MDR “Basic UDI-DI”, it shall not be encoded in a data carrier (barcode, RFID tag, etc.) See how the GMN works in the GS1 system. |
The remainder of this article outlines the work that was undertaken by the group to identify a robust check character scheme that could be used for this application of the GS1 Global Model Number as a Basic UDI-DI for EU MDR and IVDR compliance.
Protecting Manually Keyed Data
One goal of any check character scheme is to reliably detect various types of error that might be introduced when a person manually key-enters textual data read from a label or form.
For manually keyed data, the desirable properties of a check character scheme are to reliably detect the most common anomalies arising from human error or device failure while inputting data, such as:
- Single character substitution resulting from pressing the incorrect key or misreading a printed character on a label or form.
- Arbitrary substitution of multiple characters resulting from an attempt to enter data that is difficult to read.
- A character that is erroneously repeated, perhaps by pressing the correct key for too long a time.
- A character repeated, then repeated again, for example due to a stuck key.
- Transposition of two neighboring characters.
- Skip transpositions: Defined as the transposition of two characters separated by a single interposing character.
Round 1: One Check Character
Under the initial scope presented to the group, the intent was to propose an algorithm for deriving a single check character within the GS1 AI encodable character set 82 (hereafter “CSET 82”) possessing the aforementioned desirable properties.
Sum of Products modulo-N
The initial analysis was performed using many variants of a standard check character scheme in which the character positions are given various weights, and these weights are multiplied by the character value at that position (derived from the position of the character in CSET 82), and finally these products are summed to produce a total that is reduced modulo some chosen number. The result is converted back to a character at the corresponding position in CSET 82 and this becomes the check character.
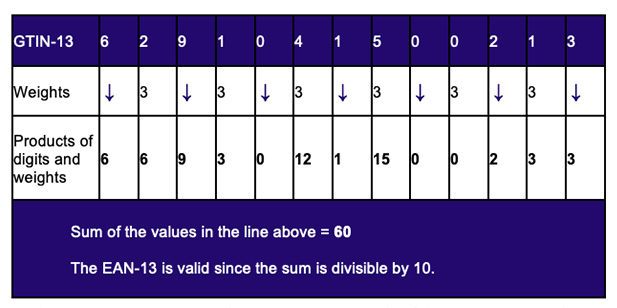
Figure 2 provides a simplified illustration of the validation of the EAN-13 barcode that is ubiquitous at Point of Sale. The EAN-13 carries a numeric identifier known as a GTIN-13 that has a modulo-10 check digit, in this example previously computed to be “3” as shown in the last box on the right. For the sake of brevity, the check digit calculation itself is not explained here although its derivation is straightforward enough.
The parameters that can be varied in such a scheme are the weights assigned to each character position and the modulus by which the sum of products is reduced. Our team performed an analysis to evaluate a number of variants of this scheme. We introduced different kinds of error (in accordance with the common errors listed above) to random messages and determined the proportion of damaged messages that went undetected for each type of damage using a given combination of weights and modulo reduction.
We tested with alternating weights (such as 1:2:1:2:… and 1:3:1:3:…), increasing and decreasing prime weights (2:3:5:7:11:…), weights with values coprime to the chosen modulus (for example, omitting the prime weight 41 if a modulus of 82 is chosen), and some other schemes.
It is well established that an optimal configuration for any simple sum-of-products check character scheme such as the team was exploring is for the modulus to be prime and relatively close to the character set size. Since it was determined that the check character for a healthcare GMN must be drawn from CSET 82 (an alphabet that consists of 82 distinct characters) this ruled out a modulus of 83, so we researched the nearest smaller primes: 79, 67, 61, …
The motivation for a prime modulus and for considering increasing-prime character position weights derives from the requirement to avoid “collisions”. Intuitively, the goal is to minimize the number of occasions where arbitrarily changing a character in two or more positions could result in changes to those characters’ contributions to the sum that exactly cancel each other or otherwise result in the same check character. Whenever this happens, the corruption of the message goes undetected.
From the various combinations of weights and moduli that we tested it was clear that each combination demonstrated deficiencies.
For example, alternating weights with a modulus of 82 guarantees the detection of neighboring character transpositions but is entirely unable to detect skip transpositions (defined in the above list of desirable properties) since the character contributions are derived under the same weights before and after transposition. Additionally, under any simple scheme with a non-prime modulus, other forms of damage such as repeated characters and errors to multiple characters have poor detection rates.
As expected for this application, distinct prime character position weights together with a prime modulus result in the best overall performance in terms of having the fewest collisions when making a number of arbitrary changes to the data. However, a significant limitation of any scheme where the valid check character elements are drawn from a character set that has fewer elements than the data being protected, is that it can never provide guaranteed detection of single-character substitutions. In particular, at every character position there will be at least two different characters that may be interchanged without detection.
This is a significant problem because single-character damage is the most frequent type of error encountered with manually keyed data.
If we want guaranteed protection against single-character substitution then we must rule out using any modulus less than 82. Yet we have already ruled out using any modulus greater than 82 on the basis that all possible check characters must belong to CSET 82. This just leaves us with a modulus of 82!
But a non-prime modulus is deficient at detecting many types of damage! So things were not looking good…
Luhn’s Algorithm, Extended
After analyzing the various sum of products modulo-N schemes the group devised a variant of Luhn’s algorithm, which is used in the validation of credit card numbers.
Luhn’s algorithm is essentially an alternating weights scheme (2:1:2:1:…) modulo-10. However, it avoids the collisions that result when the product of a character value and a weight of 2 overflows by adding 1 to the product. Thus, each possible input at a weight-2 position now makes a unique contribution to the sum of products.
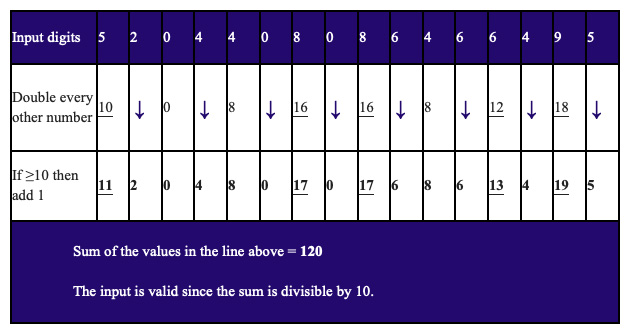
The notion was that by extending Luhn’s original algorithm from the usual set of ten digits to the full CSET 82 alphabet we could use our required modulus of 82 while avoiding the collisions normally associated with a non-prime modulus.
Indeed the resulting algorithm was shown to have the expected favorable properties:
- Single character substitution is guaranteed to be detected.
- Transposition of two neighboring characters is guaranteed to be detected, except for a single character pair that can be determined during algorithm design.
- Other common types of error, including repeated characters and multiple substitutions, go undetected only 1.2% of the time. This is as good as you can do given only a single check character that can take 82 different values (1 / 82 = 1.2%).
As with other alternating weights schemes, skip transpositions will still evade detection. However we could probably accept this considering the scheme’s excellent performance when detecting the more common types of error encountered with manual keyed data.
On the basis of its strong performance the group proposed this algorithm to GS1. We thought we were finished and had produced the best possible algorithm for this character set using a single check character. However things were not going to be this simple…
Round 2: Two Check Characters
CSET 82 includes a number of characters that are visually indistinct such as the digit “0” with the letter “O” and the digit “1” with the letter “I”. Moreover, some of the characters, such as punctuation marks and other special characters, might be difficult for novice typists to enter and may not even be present on the keyboards of specialized devices such as clean room data entry terminals.
In practice, users of the GS1 Global Model Number will generally restrict themselves to a judiciously chosen subset of CSET 82 that is supported by their incumbent technology and any relevant internal standards. However, when a GMN is used as a Basic UDI-DI the check character is to be derived by a standardized algorithm. If that algorithm were to select a check character from the full CSET 82 then this would likely present significant challenges for certain applications.
As we have seen, reducing the character set that is available for the check character would have an adverse impact on the ability of the check character validation scheme to detect data input errors, making detection of any single character substitution an impossibility and making the detection of other forms of damage much weaker due to an increased propensity for collisions.
It was therefore necessary to build a consensus that it was an absolute necessity to have two check characters protecting the data and that this pair of characters would then be drawn from a restricted subset of CSET 82 that could be easily visually distinguished and was likely to be available on most data input terminals.
The clear and inarguable findings from our research up to this point meant that such consensus was inevitable.
Further investigation by our group determined that a subset of 32 characters, denoted CSET 32, comprising the 8 numbers and 24 uppercase letters from CSET 82 as shown below would likely be most appropriate:
23456789ABCDEFGHJKLMNPQRSTUVWXYZ
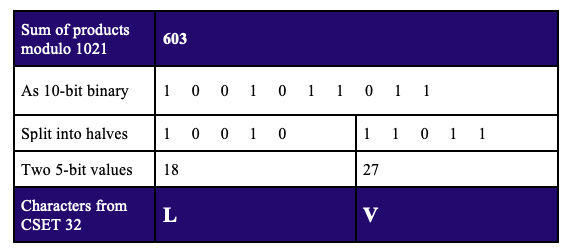
After considerable further analysis of various weights and moduli, a pair of check characters drawn from this 32-character set allowed for a base-32 scheme that used decreasing prime weights (83:79:73:71:…) with a prime modulus of 1021 (the first prime less than 322 = 1024).
The resulting ten-bit sum of products, modulo-1021, is divided in half to form two five-bit values, then the check characters are chosen by looking up the values in our new CSET 32.
Testing with random data using messages of random lengths (the Monte Carlo method) and exhaustive testing of all 3.7 billion combinations of five-character messages demonstrated the following properties.
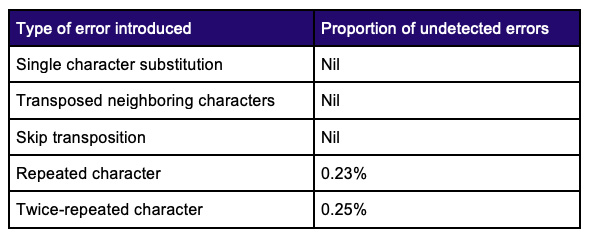
This performance was deemed to be entirely acceptable and was better than anything that was achieved during our analysis using a single check character, noting especially the perfect success rate at detecting those elusive skip transpositions!
This was the final scheme that was proposed, and accepted, for the GS1 Global Model Number when used as a Basic UDI-DI. See this link for details of the check character pair generation and verification algorithms: GS1 check character pair calculator for the GS1 Global Model Number – Basic UDI-DI.

Afterward
The project is a successful example where experts from different backgrounds and affiliations were consulted informally to solve a pressing, real-world issue. Each member brought their own strengths of analysis, simulation, communication and knowledge of the healthcare application and were motivated by their passion for problem solving and for having the best possible AIDC solutions developed and adopted. They collaborated vigorously under loosely defined rules of engagement to find and quantify multiple potential solutions to an evolving problem description, and the group delivered comprehensive results in a short amount of time.
Based on its obvious merits, the GS1 base-32 check character pair solution was subsequently adopted by the Health Industry Business Communications Council as the data security scheme for their Basic UDI-DI solution. It is generally beneficial for the industry as a whole when standards setting organizations are able to converge on a common approach to key elements of their solutions that do not require adaptation to some unique requirement.
The result was a great outcome as the European healthcare system on the whole are beneficiaries of this common approach in this aspect of the respective GS1 and HIBCC systems.
Acknowledgements
The authors would like to express our gratitude to the members of the ad hoc group for their detailed review and contributions to draft versions of this article.
Figures 1 and 6 are copyright © GS1 AISBL, reproduced from GS1 General Specifications under fair use.
Related Articles
-

On Monday, March 20, the EU MDR extension approved on March 7 came into effect…
-
The position paper from the European Commission’s Medical Device Coordination Group (MDCG) recommends an extended…
-
The partnership brings together Evidence Partners' literature review platform, DistillerSR, and Akra Team's strategic regulatory…
-
The European Commission developed the new proposal following a December 9, 2022, meeting of the…
