

An increasing number of medical devices incorporate artificial intelligence (AI) capabilities to support therapeutic and diagnostic applications. In spite of the risks connected with this innovative technology, the applicable regulatory framework does not specify any requirements for this class of medical devices. To make matters even more complicated for manufacturers, there are no standards, guidance documents or common specifications for medical devices on how to demonstrate conformity with the essential requirements.
Introduction
The term artificial intelligence (AI) describes the capability of algorithms to take over tasks and decisions by mimicking human intelligence.1 Many experts believe that machine learning, a subset of artificial intelligence, will play a significant role in the medtech sector.2,3 “Machine learning” is the term used to describe algorithms capable of learning directly from a large volume of “training data”. The algorithm builds a model based on training data and applies the experience, it has gained from the training to make predictions and decisions on new, unknown data. Artificial neural networks are a subset of machine learning methods, which have evolved from the idea of simulating the human brain.22 Neural networks are information-processing systems used for machine learning and comprise multiple layers of neurons. Between the input layer, which receives information, and the output layer, there are numerous hidden layers of neurons. In simple terms, neural networks comprise neurons – also known as nodes – which receive external information or information from other connected nodes, modify this information, and pass it on, either to the next neuron layer or to the output layer as the final result.5 Deep learning is a variation of artificial neural networks, which consist of multiple hidden neural network layers between the input and output layers. The inner layers are designed to extract higher-level features from the raw external data.
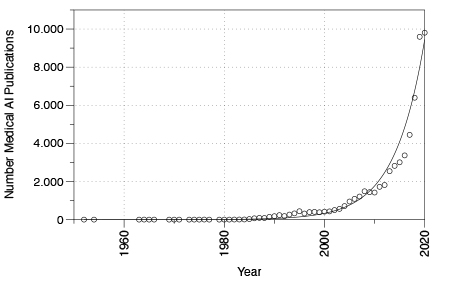
The role of artificial intelligence and machine learning in the health sector was already the topic of debate well before the coronavirus pandemic.6 As shown in an excerpt from PubMed several approaches for AI in medical devices have already been implemented in the past (see Figure 1). However, the number of publications on artificial intelligence and medical devices has grown exponentially since roughly 2005.
Regulation of AI
Artificial intelligence in the medtech sector is at the beginning of a growth phase. However, expectations for this technology are already high, and consequently prospects for the digital future of the medical sector are auspicious. In the future, artificial intelligence may be able to support health professionals in critical tasks, controlling and automating complex processes. This will enable diagnosis, therapy and care to be optimally aligned to patients’ individual needs, thereby increasing treatment efficiency, which in turn will ensure an effective and affordable healthcare sector in the future.4
However, some AI advocates tend to overlook some of the obstacles and risks encountered when artificial intelligence is implemented in clinical practice. This is particularly true for the upcoming regulation of this innovative technology. The risks of incorporating artificial intelligence in medical devices include faulty or manipulated training data, attacks on AI such as adversarial attacks, violation of privacy and lack of trust in technology. In spite of these technology-related risks, the applicable standards and regulatory frameworks do not include any specific requirements for the use of artificial intelligence in medical devices. After years of negotiations in the European Parliament, Regulation (EU) 2017/745 on medical devices and Regulation (EU) 2017/746 on in-vitro diagnostic medical devices entered into force on May 25, 2017. In contrast to Directives, EU Regulations enter directly into force in the EU Member States and do not have to be transferred into national law. The new regulations impose strict demands on medical device manufacturers and the Notified Bodies, which manufacturers must involve in the certification process of medical devices and in-vitro diagnostic medical devices (excluding class I medical devices and nonsterile class A in-vitro diagnostic medical devices, for which the manufacturer’s self-declaration will be sufficient).
Annex I to both the EU Regulation on medical devices (MDR) and the EU Regulation on in vitro diagnostic medical devices (IVDR) define general safety and performance requirements for medical devices and in-vitro diagnostics. However, these general requirements do not address the specific requirements related to artificial intelligence. To make matters even more complicated for manufacturers, there are no standards, guidance documents or common specifications on how to demonstrate conformity with the general requirements. To place a medical device on the European market, manufacturers must meet various criteria, including compliance with the essential requirements and completion of the appropriate conformity assessment procedure. By complying with the requirements, manufacturers ensure that their medical devices fulfill the high levels of safety and health protection required by the respective regulations.
To ensure the safety and performance of artificial intelligence in medical devices and in-vitro diagnostics, certain minimum requirements must be fulfilled. However, the above regulations define only general requirements for software. According to the general safety and performance requirements, software must be developed and manufactured in keeping with the state of the art. Factors to be taken into account include the software lifecycle process and risk management. Beyond the above, repeatability, reliability and performance in line with the intended use of the medical device must be ensured. This implicitly requires artificial intelligence to be repeatable, performant, reliable and predictable. However, this is only possible with a verified and validated model. Due to the absence of relevant regulatory requirements and standards, manufacturers and Notified Bodies are determining the “state of the art” for developing and testing artificial intelligence in medical devices, respectively. During the development, assessment and testing of AI, fundamental differences between artificial intelligence (particularly machine learning) and conventional software algorithms become apparent.
Credibility and trust in AI
Towards the end of 2019, and thus just weeks before the World Health Organization’s (WHO) warning of an epidemic in China, a Canadian company (BlueDot) specializing in AI-based monitoring of the spread of infectious diseases alerted its customers to the same risk. To achieve this the company’s AI combed through news reports and databases of animal and plant diseases. By accessing global flight ticketing data, the AI system correctly forecast the spread of the virus in the days after it emerged. This example shows the high level of performance that can already be achieved with artificial intelligence today.7 However, it also reveals one of the fundamental problems encountered with artificial intelligence: Despite the distribution of information of the outbreak to various health organizations in different countries, international responses were few. One reason for this lack of response to the AI-based warning is the lack of trust in technology that we do not understand, which plays a particularly significant role in medical applications.
In clinical applications, artificial intelligence is predominantly used for diagnostic purposes. Analysis of medical images is the area where the development of AI models is most advanced. Artificial intelligence is successfully used in radiology, oncology, ophthalmology, dermatology and other medical disciplines.2 The advantages of using artificial intelligence in medical applications include the speed of data analysis and the capability of identifying patterns invisible to the human eye.
Take the diagnosis of osteoarthritis, for example. Although medical imaging enables healthcare professionals to identify osteoarthritis, this is generally at a late stage after the disease has already caused some cartilage breakdown. Using an artificial-intelligence system, a research team led by Dr. Shinjini Kundu analyzed magnetic resonance tomography (MRT) images. The team was able to predict osteoarthritis three years before the first symptoms manifested themselves.8 However, the team members were unable to explain how the AI system arrived at its diagnosis. In other words, the system was not explainable. The question now is whether patients will undergo treatment such as surgery, based on a diagnosis made by an AI system, which no doctor can either explain or confirm.
Further investigations revealed that the AI system identified diffusion of water into cartilage. It detected a symptom invisible to the human eye and, even more important, a pattern that had previously been unknown to science. This example again underlines the importance of trust in the decision of artificial intelligence, particularly in the medtech sector. Justification of decisions is one of the cornerstones of a doctor-patient (or AI-patient) relationship based on mutual trust. However, to do so the AI system must be explainable, understandable and transparent. Patients, doctors and other users will only trust in AI systems if their decisions can be explained and understood.
Differences Compared to the Regulation of Conventional Algorithms
Many medical device manufacturers wonder why assessment and development of artificial intelligence must follow a different approach to that of conventional software. The reason is based on the principles of how artificial intelligence is developed and how it performs. Conventional software algorithms take an input variable X, process it using a defined algorithm and supply the result Y as the output variable (if X, then Y). The algorithm is programmed, and its correct function can be verified and validated. The requirements for software development, validation and verification are described in the two standards IEC 62304 and IEC 82304-1. However, there are fundamental differences between conventional software and artificial intelligence implementing a machine learning algorithm. Machine learning is based on using data to train a model without explicitly programming the data flow line by line. As described above, machine learning is trained using an automated appraisal of existing information (training data). Given this, both the development and conformity assessment of artificial intelligence necessitate different standards. The following sections provide a brief overview of the typical pitfalls.
Explainability of AI
A major disadvantage of artificial intelligence, in particular machine learning based on neural networks, is the complexity of the algorithms. This makes them highly non-transparent, hence their designation of “black-box AI” (see Figure 2). The complex nature of AI algorithms not only concerns their mathematical description but also—in the case of deep-learning algorithms—their high level of dimensionality and abstraction. For these classes of AI, the extent to which input information contributes to a specific decision is mostly impossible to determine. This is why AI is often referred to as “black box AI”. Can we trust the prediction of the AI system in such a case and, in a worst-case scenario, can we identify a failure of the system or a misdiagnosis?
A world-famous example of the result of a “black-box AI” was the match between AlphaGo, the artificial intelligence system made by DeepMind (Google) and the Go world champion, Lee Sedol. In the match, which was watched by an audience of 60 million including experts, move 37 showed the significance of these particular artificial intelligence characteristics. The experts described the move as a “mistake”, predicting that AlphaGo would lose the match since in their opinion the move made no sense at all. In fact, they went even further and said, “It’s not a human move. I’ve never seen a human play this move”9.
None of them understood the level of creativity behind AlphaGo’s move, which proved to be critical for winning the match. While understanding the decision made by the artificial intelligence system would certainly not change the outcome of the match, it still shows the significance of the explainability and transparency of artificial intelligence, particularly in the medical field. AlphaGo could also have been “wrong”!
One example of AI with an intended medical use was the application of artificial intelligence for determining a patient’s risk of pneumonia. This example shows the risk of black-box AI in the MedTech sector. The system in question surprisingly identified the high-risk patients as non-significant.10 Rich Caruana, one of the leading AI experts at Microsoft, who was also one of the developers of the system, advised against the use of the artificial intelligence he had developed: “I said no. I said we don’t understand what it does inside. I said I was afraid.”11
In this context, it is important to note that “open” or “explainable” artificial intelligence, also referred to as “white box”, is by no means inferior to black-box AI. While there have been no standard methods for “opening” the black box, there are promising approaches for ensuring the plausibility of the predictions made by AI models. Some approaches try to achieve explainability based on individual predictions on input data. Others, by contrast, try to limit the range of input pixels that impact the decisions of artificial intelligence.12
Right to Explainability
Medical devices and their manufacturers must comply with further regulatory requirements in addition to the Medical Device Regulation (MDR) and the In-vitro Diagnostics Regulation (IVDR). The EU’s General Data Protection Regulation (GDPR), for instance, is of particular relevance for the explainability of artificial intelligence. It describes the rules that apply to the processing of personal data and is aimed at ensuring their protection. Article 110 of the Medical Device Regulation (MDR) explicitly requires measures to be taken to protect personal data, referencing the predecessor of the General Data Protection Regulation.
AI systems which influence decisions that might concern an individual person must comply with the requirements of Articles 13, 22 and 35 of the GDPR.
“Where personal data … are collected…, the controller shall… provide….the following information: the existence of automated decision-making … and… at least in those cases, meaningful information of the logic involved…”13
In simple terms this means, that patients who are affected by automated decision-making must be able to understand this decision and have the possibility to take legal action against it. However, this is precisely the type of understanding which is not possible in the case of black box AI. Is a medical product implemented as black-box AI eligible for certification as a medical device? The exact interpretation of the requirements specified in the General Data Protection Regulation is currently the subject of legal debate.14
Verification and Validation of the AI model
The Medical Device Regulation places manufacturers under the obligation to ensure the safety of medical devices. Among other specifications, Annex I to the regulation includes, , requirements concerning the repeatability, reliability and performance of medical devices (both for stand-alone software and software embedded into a medical device):
“Devices that incorporate electronic programmable systems, including software, … shall be designed to ensure repeatability, reliability and performance in line with their intended use.“ (MDR Annex I, 17.1)15
Compliance with general safety and performance requirements can be demonstrated by utilizing harmonized standards. Adherence to a harmonized standard leads to the assumption of conformity, whereby the requirements of the regulation are deemed to be fulfilled. Manufacturers can thus validate artificial intelligence models in accordance with the ISO 13485:2016 standard, which, among other requirements, describes the processes for the validation of design and development in clause 7.3.7.
For machine learning two independent sets of data must be considered. In the first step, one set of data is needed to train the AI model. Subsequently, another set of data is necessary to validate the model. Validation of the model should use independent data and can also be performed by cross-validation in the meaning of the combined use of both data sets. However, it must be noted that AI models can only be validated using an independent data set. Now, which ratio is recommended for the two sets of data? This is not an easy question to answer without more detailed information about the characteristics of the AI model. A look at the published literature (state of the art) recommends a ratio of approx. 80% training data to approx. 20% validation data. However, the ratio being used depends on many factors and is not set in stone. The notified bodies will continue to monitor the state of the art in this area and, within the scope of conformity assessment, also request the reasons underlying the ratio used.
Another important question concerns the number of data sets. As the number of data sets depends on the following factors, this issue is difficult to assess, depending on:
- Number of properties or dimensionality of data
- Statistical distribution of data
- Learning methods used
- Other characteristics
Generally, the larger the number of data the more performant the model can be assumed to work. In their publication on speech recognition, Banko and Brill from Microsoft state, “…After throwing more than one billion words within context at the problem, any algorithm starts to perform incredibly well…”16
At the other end of the scale, i.e. the minimum number of data sets required, “computational learning theory” offers approaches for estimating the lower threshold. However, general answers to this question are not yet known and these approaches are based on ideal assumptions and only valid for simple algorithms.
Manufacturers need to look not only at the number of data, but also at the statistical distribution of both sets of data. To prevent bias, the data used for training and validation must represent the statistical distribution of the environment of application. Training with data that are not representative will result in bias. The U.S. healthcare system, for example, uses artificial intelligence algorithms to identify and help patients with complex health needs. However, it soon became evident that where patients had the same level of health risks, the model suggested Afro-Americans less often for enrolment in these special high-risk care management programs.17 Studies carried out by Obermeyer, et al. showed the cause for this to be racial bias in training data. Bias in training data not only involves ethical and moral aspects that need to be considered by manufacturers: it can also affect the safety and performance of a medical device. Bias in training data could, for example, result in certain indications going undetected on fair skin.
Data Quality
Many deep learning models rely on a supervised learning approach, in which AI models are trained using labelled data. In cases involving labelled data, the bottleneck is not the number of data, but the rate and accuracy at which data are labeled. This renders labeling a critical process in model development. At the same time, data labelling is error-prone and frequently subjective, as it is mostly done by humans. Humans also tend to make mistakes in repetitive tasks (such as labelling thousands of images).
Labeling of large data volumes and selection of suitable identifiers is a time- and cost-intensive process. In many cases, only a very minor amount of the data will be processed manually. These data are used to train an AI system. Subsequently the AI system is instructed to label the remaining data itself—a process that is not always error-free, which in turn means that errors will be reproduced.7 Nevertheless, the performance of artificial intelligence combined with machine learning very much depends on data quality. This is where the accepted principle of “garbage in, garbage out” becomes evident. If a model is trained using data of inferior quality, the developer will also obtain a model of the same quality.
Adversarial Learning and Instabilities of Deep Learning Algorithms
Other properties of artificial intelligence that manufacturers need to take into account are adversarial learning problems and instabilities of deep learning algorithms. Generally, the assumption in most machine learning algorithms is that training and test data are governed by identical distributions. However, this statistical assumption can be influenced by an adversary (i.e., an attacker that attempts to fool the model by providing deceptive input). Such attackers aim to destabilize the model and to cause the AI to make false predictions. The introduction of certain adversarial patterns to the input data that are invisible to the human eye causes major errors of detection to be made by the AI system. In 2020, for example, the security company McAfee demonstrated their ability to trick Tesla’s Mobileye EyeQ3 AI System into driving 80 km/h over the speed limit, simply by adding a 5 cm strip of black tape to a speed limit sign.24
AI methods used in the reconstruction of MRT and CT images have also proved unstable in practice time and again. A study investigating six of the most common AI methods used in the reconstruction of MRT and CT images proved these methods to be highly unstable. Even minor changes in the input images, invisible to the human eye, result in completely distorted reconstructed image.18 The distorted images included artifacts such as removal of tissue structures, which might result in misdiagnosis. Such an attack may cause artificial intelligence to reconstruct a tumor at a location where there is none in reality or even remove cancerous tissue from the real image. These artifacts are not present when manipulated images are reconstructed using conventional algorithms.18
Another vulnerability of artificial intelligence concerns image-scaling attacks. This vulnerability has been known since as long ago as 2019.19 Image-scaling attacks enable the attacker to manipulate the input data in such a way that artificial intelligence models with machine learning and image scaling can be brought under the attacker’s control. Xiao et al., for example, succeeded in manipulating the well-known machine-learning scaling library, TensorFlow, in such a manner that attackers could even replace complete images.19 An example of such an image-scaling attack is shown in Figure 3. In this scaling operation, the image of a cat is replaced by an image of a dog. Image-scaling attacks are particularly critical as they can both distort training of artificial intelligence and influence the decisions of artificial intelligence trained using manipulated images.

Adversarial attacks and stability issues pose significant threats to the safety and performance of medical devices incorporating artificial intelligence. Especially concerning is the fact that the conditions of when and where the attacks could occur, are difficult to predict. Furthermore, the response of AI to adversarial attacks is difficult to specify. If, for instance, a conventional surgical robot is attacked, it can still rely on other sensors. However, changing the policy of the AI in a surgical robot might lead to unpredictable behavior and by this to catastrophic (from a human perspective) responses of the system. Methods to address the above vulnerabilities and reduce susceptibility to errors do exist. For example, the models can be subjected to safety training, making them more resilient to the vulnerabilities. Defense techniques such as “adversarial training” and “defense distillation” have already been practiced successfully in image reconstruction algorithms.21 Further methods include human-in-the-loop approaches, as human’s performance is strongly robust against adversarial attacks targeting AI systems. However, this approach has limited applicability in instances where humans can be directly involved.25
Outlook for AI Regulation in the MedTech Sector
Although many medical devices using artificial intelligence have already been approved, the regulatory pathways in the medtech sector are still open. At present no laws, common specifications or harmonized standards exist to regulate AI application in medical devices. In contrast to the EU authorities, the FDA published a discussion paper on a proposed regulatory framework for artificial intelligence in medical devices in 2019. The document is based on the principle of risk management, software-change management, guidance on the clinical evaluation of software and a best-practice approach to the software lifecycle.20 in 2021, the FDA published their action plan on furthering AI in medical devices. The action plan consists of five next steps, with the foremost being to develop a regulatory framework explicitly for change control of AI, a good machine learning practice and new methods to evaluate algorithm bias and robustness 26
In 2020 the European Union also published a position paper on the regulation of artificial intelligence and medical devices. The EU is currently working on future regulation, with a first draft expected in 2021.
China’s National Medical Products Administration (NMPA) published the “Technical Guiding Principles of Real-World Data for Clinical Evaluation of Medical Devices” guidance document. It specifies obligations concerning requirements-analysis, data collection and processing, model definition, verification, and validation as well as post-market surveillance.
Japan’s Ministry of Health, Labour and Welfare is working on a regional standard for artificial intelligence in medical devices. However, to date this standard is available in Japanese only. Key points of assessment are plasticity the predictability of models, quality of data and degree of autonomy. 27
In Germany, the Notified Bodies have developed their own guidance for artificial intelligence. The guidance document was prepared by the Interest Group of the Notified Bodies for Medical Devices in Germany (IG-NB) and is aimed at providing guidance to Notified Bodies, manufacturers and interested third parties. The guidance follows the principle that the safety of AI-based medical devices can only be achieved by means of a process-focused approach that covers all relevant processes throughout the whole life cycle of a medical device. Consequently, the guidance does not define specific requirements for products, but for processes.
The World Health Organization, too, is currently working on a guideline addressing artificial intelligence in health care.
Conclusion
Artificial intelligence is already used in the medtech sector, albeit currently somewhat sporadically. However, at the same time the number of AI algorithms certified as medical devices has increased significantly over the last years.28 Artificial intelligence is expected to play a significant role in all stages of patient care. According to the requirements defined in the Medical Device Regulation, any medical device, including those incorporating AI, must be designed in such a way as to ensure repeatability, reliability and performance according to its intended use. In the event of a fault condition (single fault condition), the manufacturer must implement measures to minimize unacceptable risks and reduction of the performance of the medical device (MDR Annex I, 17.1). However, this requires validation and verification of the AI model.
Many of the AI models used are “black-box” models. In other words, there is no transparency in how these models arrive at their decisions. This poses a problem where interpretability and trustworthiness of the systems are concerned. Without transparent and explainable AI predictions, the medical validity of a decision might be doubted. Some current errors of AI in pre-clinical applications might fuel doubts further. Explainable and approvable AI decisions are a prerequisite for the safe use of AI on actual patients. This is the only way to inspire trust and maintain it in the long term.
The General Data Protection Regulation demands a high level of protection of personal data. Its strict legal requirements also apply to processing of sensitive health data in the development or verification of artificial intelligence.
Adversarial attacks aim at influencing artificial intelligence, both during the training of the model and in the classification decision. These risks must be kept under control by taking suitable measures.
Impartiality and fairness are important, safety-relevant, moral and ethical aspects of artificial intelligence. To safeguard these aspects, experts must take steps to prevent bias when training the system.
Another important question concerns the responsibility and accountability of artificial intelligence. Medical errors made by human doctors can generally be traced back to the individuals, who can be held accountable if necessary. However, if artificial intelligence makes a mistake the lines of responsibility become blurred. For medical devices on the other hand, the question is straightforward. The legal manufacturer of the medical device incorporating artificial intelligence must ensure the safety and security of the medical device and assume liability for possible damage.
Regulation of artificial intelligence is likewise still at the beginning of development involving various approaches. All major regulators around the globe have defined or are starting to define requirements for artificial intelligence in medical devices. A high level of safety in medical devices will only be possible with suitable measures in place to regulate and control artificial intelligence—but this must not impair the development of technical innovation.
Follow to Page 2 for References.
Related Articles
-

The UK MHRA has published “Software and Artificial Intelligence as a Medical Device.” The guidance…
-

“Using Artificial Intelligence and Machine Learning in the Development of Drug and Biological Products” and…
-

Embracing compliance is a continuous process, and investing in agile technologies that streamline workflows—especially in…
-

The increase in global regulatory demands for medical devices has presented new challenges for regulatory…