

Opportunities for innovators in the intelligent medical device market abound. Healthcare providers the world over are eager for solutions that enable them to leverage empirical data to make fact-based clinical decisions and to become less reliant on the experience and knowledge of any individual clinician.
Just as important, a variety of technical advances—including the computing power now available in small form-factors and an abundance of cheap network bandwidth—make it more practical than ever for device manufacturers to capture and deliver high-value data to clinicians and researchers.
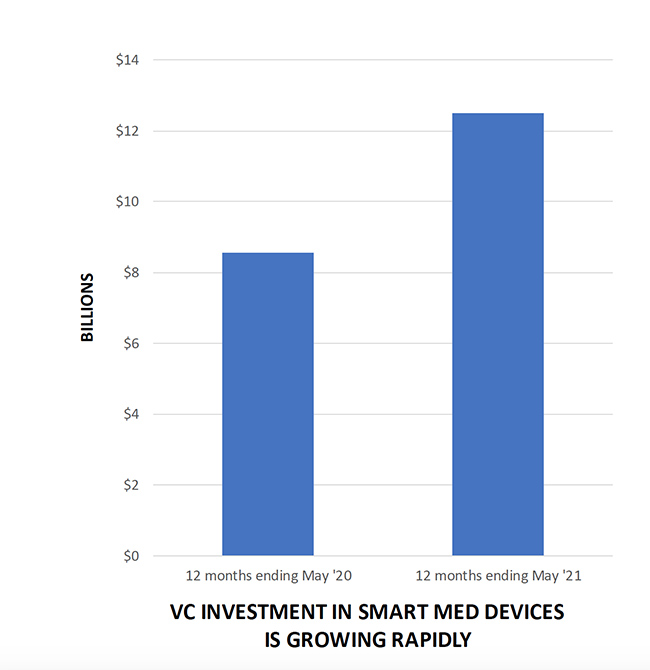
That’s why the so-called Internet of Medical Things (IoMT) market alone, which accounts for just a portion of all smart medical devices, is projected to grow from $24.4 billion in 2019 to $285.5 billion in 2029.1 And it’s why venture investments in new device development has grown an astounding 46% YoY to $12.5 billion as of May 2021 (see Figure 1).2
Nobody, however, is going to invest in your startup if all you have is a good idea. After all, the “intelligence” of any intelligent device is a function of its data and how that data is leveraged to maximize value to the customer. So if you can’t present potential investors with a solid data game-plan and a demonstrable ability to execute on that plan, it’s going to be hard to get past your seed round.
Plus, even if you are convincing enough to sell investors on your startup’s worth well enough to get through a few funding rounds, you’re going have a ton of trouble going live to market without a sophisticated, purpose-specific data architecture.
Sadly, many smart device startups find themselves in a classic chicken-and-egg conundrum when it comes to their data architecture. They need to show enough progress on that architecture to impress potential participants in their next round of funding—but the limited financial resources at their disposal from the last round of financing constrain their ability to achieve that progress.
Or, as I like to put it, smart medical device startups must repeatedly hit data capability milestones that will impress investors at funding round N within the resource constraints of funding round N-1.
Data Architecture Is a Hard Climb
A variety of factors make it extremely difficult to build an effective data architecture for smart device startups. These factors include:
- Diversity of data and use-cases. Medical device manufacturers don’t just need to capture and analyze data from individual patients for one-time analyses. They also need to capture and analyze data from individual devices for QA, customer support, and lifecycle upgrades. And like every other company, they need to track customer data from marketing and sales through ongoing account management—which must also correlate with the manufacturing date, serial number, and historical use of the devices in use by that account.
- Complexity and diversity of data operations. To deliver maximum value to customers, medical device startups can’t merely collect data. They must also operate, correlate and communicate that data to external and internal constituencies in whatever way makes it most comprehensible and actionable. Potential investors also need confidence in a startup’s mastery of all the disciplines essential for success in today’s data-centric marketplace: analytics, ML, AI, visualization, etc.
- Security and compliance. Medical device startups face an especially onerous data architecture challenge since—above and beyond all the other data magic they have to do—they also have to comply with the stringent regulations governing healthcare data and maintain a high level of data security. This isn’t just a technical challenge. It’s also a knowledgebase challenge, because regulations are constantly changing and differ significantly across geographies.
- Third-party integration. Intelligent medical devices are not deployed in a vacuum. For one thing, clinicians will typically want to integrate any device they use into their broader diagnostic/therapeutic data environments. Also device makers may encounter market opportunities that entail partnership (and therefore tight integration) with other medical technology vendors. An effective data architecture will make it as easy as possible to take advantage of these opportunistic integrations.
In addition to these factors, startups face two more:
- Constrained resources. As noted above, between seed funding and launch, device startups must repeatedly hit the data architecture milestones that will impress investors at funding round N within the resource constraints of funding round N-1. These constraints limit the number of person-hours startups can devote to architecture construction, as well as their access to the diverse skill sets required for technical excellence.
- Requirements in flux. It would be nice if startups accurately understood all of their ultimate data architecture requirements from day one. But that’s simply not the case. Nor should it be—because success in tech depends on listening to your customers and keeping pace with their rapidly evolving needs. So startups have to build quickly and resource-efficiently without ever painting themselves into a corner that impedes their ability to build what the market really needs.
Alternative Approaches to Startup Buildouts
There are theoretically as many ways for startups to skin the data architecture cat as there are startups. In general, however, startups take one of the following paths.
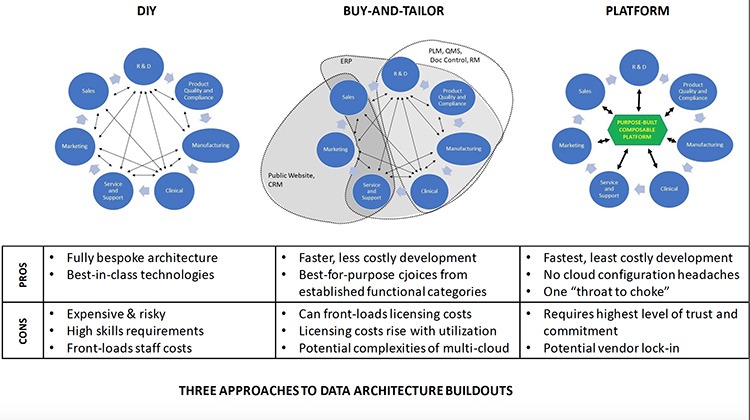
Alternative #1: DIY
Under this model, a startup’s developers take on the entire burden of building their data architecture from scratch, using some combination of proprietary and open-source tools and components. This approach naturally requires the startup to on-board a full complement of data and analytics skills—as well as enough bodies (whether in-house or contracted) to ensure timely achievement of all funding-linked data architecture milestones.
Alternative #2: Buy-and-tailor
Under this model, startups leverage a handful of best-in-class software solutions (such as popular enterprise SaaS offerings for ERP, CRM, PLM, and/or IoT connectivity) to address various portions of the buildout lifecycle. By extending, custom-configuring, and integrating these offerings, startups can meet their needs—although the work and expertise required to do so can be significant.
Alternative #3: Purpose-built platform
Under this model, startups piggyback on a data architecture platform purpose-built for the smart device go-to-market lifecycle. Ideally, such a platform should provide all underlying functional components for data management, analytics, visualization, compliance, cloud provisioning, and the like—while enabling custom configuration as necessary for the startup’s particular use-cases.
Again, every startup’s approach is ultimately different. And some startups may even mix-and-match certain aspects of the three alternatives above. But each approach has its own pros and cons, so startup founders need to map out their approach as early as possible in order to rightsize their budgets, target their recruiting, and commit to fulfillable timelines (see Figure 2).
The Funding Conundrum
While each of the above approaches to data architecture build-out has its own pros and cons, none inherently addresses the fundamental startup conundrum “How do we hit the sequential data architecture milestones we need to win investors for each sequential funding round N within the resource constraints imposed on us by each funding round N-1?”
Successfully addressing this conundrum requires more than just choosing the right overall approach from the three options above (and their possible combinations). Startup founders also need an approach that allows them to only spend what’s needed for the very next data architecture milestone N—while at the same time ensuring that this short-term focus on the next milestone in no way compromises their ability to achieve their longer-term objectives.
This staged, one-milestone-at-a-time data architecture spend has two cost components: Person-hour costs and software licensing costs. If you devise a way to keep your staged spending on these two line-items—labor and licensing—synched with each of your funding rounds, you’ll have an economically and technically rational path from seed to go-live. If not, you’ll spend that entire journey in either financial crisis, technical crisis, or both.
The issue of skilled person-hour costs is not a trivial one. Few if any startups can afford to onboard a complete enterprise-class data architecture team on day one. And subcontracting any significant portion of that original build team can lead to real codebase management and IP issues down the road.
The issue of software licensing costs is similarly non-trivial. Baseline licensing costs for best-in-class enterprise SaaS offerings can be hefty, and those costs are typically incurred upon deployment—regardless of whether or not the full functionality of the baseline offering is really required for any given milestone.
Simply put, the founders of any smart medical device startup must figure out how they can defer any and all people costs and licensing costs that are not essential for their immediate data architecture requirements.
This is not an issue that any startup founder should take lightly. Medical device startups typically fail because they either run out of money or screw up their data architecture early on (which causes costly reworkings that likewise cause them to run out of money and/or fail to meet the market’s functional data requirements).
This is also not an issue that fits neatly into either the “business management” or “technology management” bucket. The formulation of a well-staged data architecture buildout plan that synchs tightly with projected funding rounds requires close collaboration between the finance team and the tech team—and, as we all know, that collaboration doesn’t always work as smoothly as we’d all like it to work.
The good news is that the stages of a startup’s data architecture buildout almost invariably follow a fairly predictable pattern (see Figure 3). This pattern can be predicted because startups themselves follow a fairly predictable pattern. Initial R&D precedes initial manufacturing. Manufacturing precedes clinical trials. Clinical trials precede any full-blown sales effort. And that sales effort precedes the need for scalable service/support.
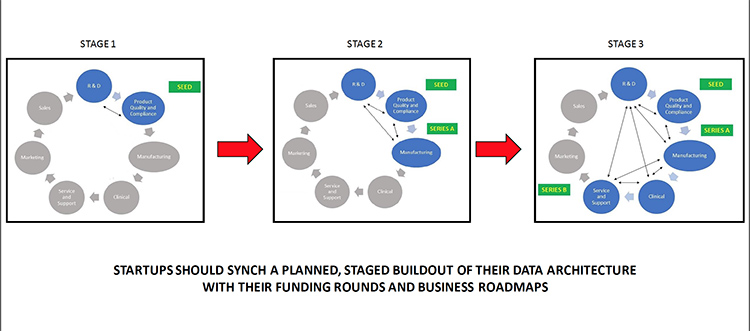
So by conceiving data architecture as not only as a desired end-state, but also as an end-state that can be achieved in well-defined, preplanned stages that map to both that startup lifecycle and the startup funding cycle, startup founders can avoid the pitfalls that so often afflict—and even sink—industry innovators.
Our advice to smart medical device startups is to therefore make staged/synched spending on data architecture one of the very first items of business. You can’t just wing these decisions when you get to your A or B funding round. You have to have a start-to-finish plan—even though contingencies may require you to diverge from that plan at some point.
And you may also have to negotiate with your software partners-of-choice in advance for a staged licensing structure that doesn’t force you to take a single dollar out of your bank account any sooner than absolutely necessary.
References
- “Global Internet of Things Trends, Analysis, and Forecast”. (July 2020). Prophecy Market Insights.
- Global Data deals database. (June 2021).
Related Articles
-

The MDDT program was developed in collaboration with the National Institutes of Health’s (NIH’s) National Institute of Drug Abuse (NIDA), National Institute of Dental Craniofacial Research (NIDCR) and National Cancer Institute (NCI) as a way for the FDA to qualify…
-

The competition will explore the feasibility, resources and infrastructure needed to integrate real-world healthcare system data into AHRQ’s systematic review findings to improve healthcare practice. The top award winner could earn up to $200,000.
-

“We are excited that organizations like Innovaccer are working to improve trust in clinical data and help ensure the data’s accuracy and broader usability.”
-

The FDA has granted several exemptions to its Medical Device Reporting requirements related to events identified in certain real-world data sources, such as medical device registries.